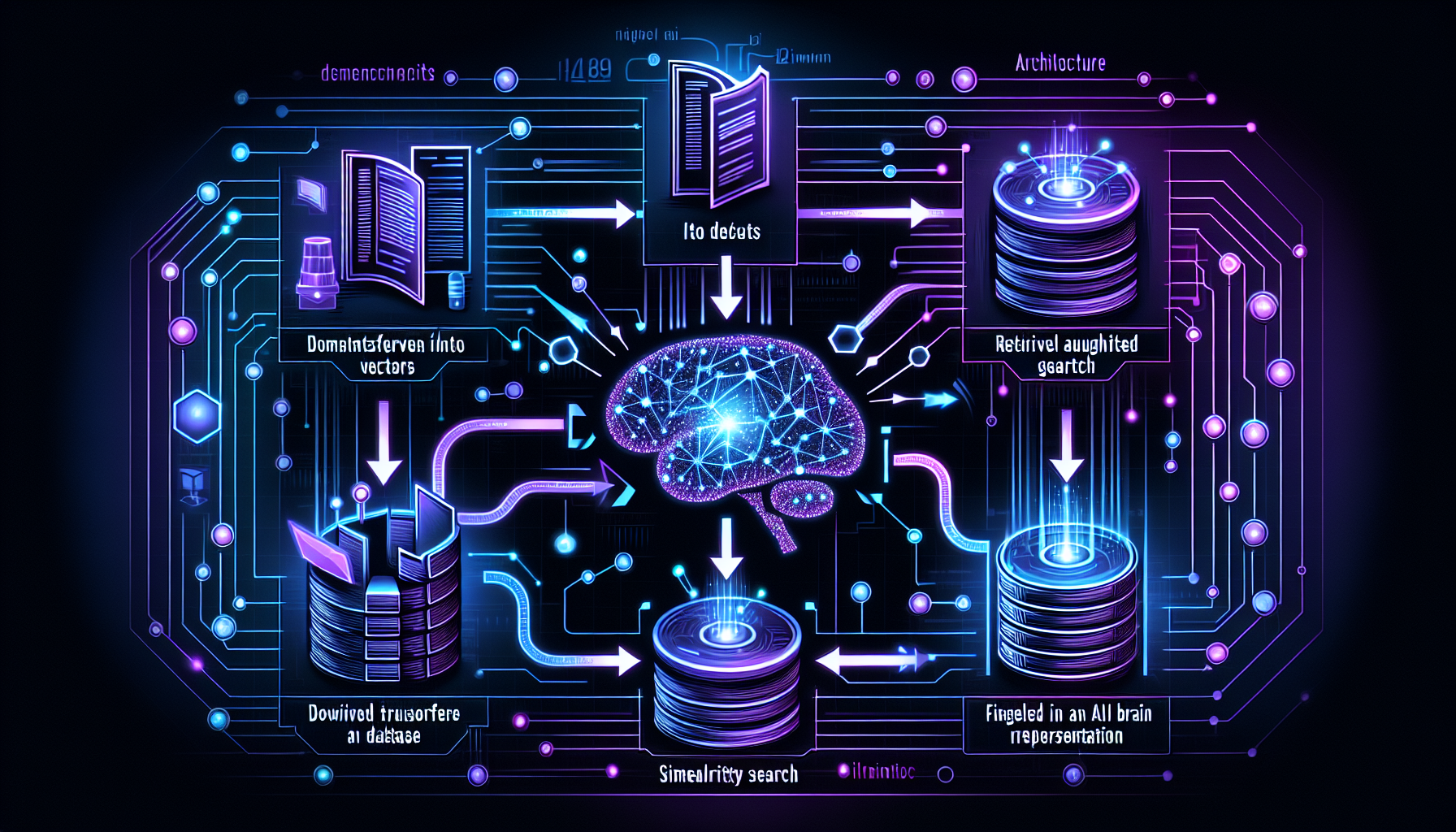
Retrieval-Augmented Generation (RAG) has become one of the most important architectural patterns in modern AI applications. By combining the reasoning capabilities of large language models with external knowledge retrieval, RAG systems deliver accurate, up-to-date responses grounded in real data.
A typical RAG pipeline consists of three stages: document ingestion (chunking, embedding, and indexing), retrieval (semantic search against a vector store), and generation (feeding retrieved context to an LLM alongside the user query). Each stage offers opportunities for optimization.
Chunking strategy significantly impacts retrieval quality. Overlapping chunks with semantic boundaries outperform simple fixed-size splits. Embedding model selection matters too, with models like text-embedding-3-large offering superior retrieval accuracy for technical content.
When building production RAG systems, focus on retrieval quality metrics, implement re-ranking for improved precision, and consider hybrid search combining dense and sparse retrieval for the best results.


Leave a Reply